REL: Release 1.3.0 #496
Merged
REL: Release 1.3.0 #496
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
- Skip redundant `get_pretrained_model` test. Co-authored by: @shaneahmed
Add support for SVS and OME-TIFF using tifffile, imagecodecs, zarr. Other TIFF formats can be supported in the future and potentially move away from relying on OpenSlide. The bulk of the work in adding support for TIFF format in tiatoolbox is extracting and normalising the metadata. This needs extensive testing (unit and battle testing). The implementation of this class is very similar to that of the Omnyx JP2 reader with glymur, just with more metadata parsing. ### Work Log 1. Add dependencies for tiffile, imagecodecs, zarr. 2. Add TIFFWSIReader class. 3. Bug fixing (in metadata parsing for SVS and zarr grouping). Co-authored-by: @John-P
Make spelling checks a blocking pre-commit issue again and sort pre-commit flake8 dependency lines to be alphabetical. Max complexity can be ignored using # noqa: C901 flag. Co-authored by: @John-P
Modified docstrings so that they synchronised with readthedocs. Changed: - Semantic segmentation docs - Deep feature extractor docs Co-authored-by: @simongraham
- Move `get_wsireader` to a `WSIReader.open` static method and add a deprecation notice to `get_wsireader`. Co-authored-by: @John-P
…functionality (#167) - Add new example notebook based on the semantic segmentation functionality. In this notebook I tried to show two things: 1- How easy it is to to use pretrained segmentation models 2- How a user can use their own segmentation model in the process. Co-authored by: @mostafajahanifar
- Bump version: 0.7.0 → 0.8.0 ### Major Updates and Feature Improvements - Adds `SemanticSegmentor` which is Predictor equivalent for semantic segmentation. - Add `TIFFWSIReader` class to support OMETiff reading. - Adds `FeatureExtractor` API to controller. - Adds WSI Serialization Dataset which support changing parallel workers on the fly. This would reduce the time spent to create new worker for every WSI/Tile (costly). - Adds IOState data class to contain IO information for loading input to model and assembling model output back to WSI/Tile. - Minor updates for `get_coordinates` to pave the way for getting patch IO for segmentation. - Migrates old code to new variable names (patch extraction, patch wsi model). - Change in API from `pretrained_weight` to `pretrained_weights`. - Adds cli for semantic segmentation. - Update python notebooks to add `read_rect` and `read_bounds` examples with `mpp` read. ### Changes to API - Adds `WSIReader.open`. `get_wsireader` will deprecate in the next release. Please use `WSIReader.open` instead. - CLI is now POSIX compatible - Replaces underscores in variable names with hyphens - Models API updated to use `pretrained_weights` instead of `pretrained_weight`. - Move string_to_tuple to tiatoolbox/utils/misc.py ### Bug Fixes and Other Changes - Fixes README git clone instructions. - Fixes stain normalisation due to changes in sklearn. - Fixes a test in tests/test_slide_info - Fixes readthedocs documentation issues ### Development related changes - Adds dependencies for tiffile, imagecodecs, zarr. - Adds more stringent pre-commit checks - Moved local test files into `tiatoolbox/data`. - Fixed `Manifest.ini` and added `tiatoolbox/data`. This means that this directory will be downloaded with the package. - Using `pkg_resources` to properly load bundled resources (e.g. `target_image.png`) in `tiatoolbox.data`. - Removed duplicate code in `conftest.py` for downloading remote files. This is now in `tiatoolbox.data._fetch_remote_file`. - Fixes errors raised by new flake8 rules. - Remove leading underscores from fixtures. - Rename some remote sample files to make more sense. - Moves all cli commands/options from cli.py to cli_commands to make it clean and easier to add new commands - Removes redundant tests - Updates to new GitHub organisation name in the repo - Fixes related links Co-authored by: TIA-Centre
- Update licence block for tiatoolbox - run isort and black on all the files. Co-authored by: @shaneahmed
- Change `models.controller` API to `models.engine` Co-authored by: @Srijay-lab
* UPD: change read space to match assumption in doc * UPD: rename
* UPD: update ioconfig def and delegation * UPD: add tests * UPD: fix format * UPD: turn on Travis * UPD; fix enumerate * UPD: add flags * UPD: add tests * UPD: delegate to merge func * UPD: fix flags * UPD: fix license
- Update links for katherdataset - Use small sample for kather test. Full zip is only for local tests. Co-authored by: @shaneahmed
- Reduce the size of images for tests to reduce running time on Travis CI. Co-authored by: @vqdang
Introducing `stainaugment` tool for generating stain-augmented images from an input image. This class can be used stand-alone or in albumentations augmentation pipelines.
The process works as bellow:
1. H&E parts of the input images are first extracted, using a predefined `stain_matrix` or a `stain_matrix` that has been calculated based on 'Vahadane' or 'Macenko' methods.
2. Input image's stain concentrations are calculated based on the provided/extracted `stain_matrix`.
3. Stain concentrations are adjusted randomly based on two input `sigma1` and `sigma2` parameters:
* Scaled by `alpha = np.random.uniform(1 - self.sigma1, 1 + self.sigma1)`
* Biased by `beta = np.random.uniform(-self.sigma2, self.sigma2)`
4. New image is formed based on the adjusted concentrations.
Providing the pre-extracted `stain_matrix` on class initialization have two benefits:
- `stainaugment` can be used for small patches on-the-fly during the model training (because the bulk of stain matrix extraction or dictionary learning is eliminated)
- By setting the parameters, this function allow the user to augment the stain around a target stain matrix i.e., normalize the stain to a target image and then augment it.
- Class definition and structure
- Check the functionality
- Add support for albumentations
- Complete the docstring and writing examples
- Complete the test and coverage
Co-authored by: @mostafajahanifar
- Add HoVerNet Architecture and associated post-processing methods - Add Nucleus Instance Segmentor to specifically deal with nucleus instance segmentation on WSI levels - Add metric function to assess detection quality. - F1 detection basing matching point sets. - Add function to overlay instance prediction onto canvas or image. May need another PR to actually improve the doc and better explain the post-processing scheme. Co-authored by: @vqdang
- Add a new example notebook on semantic segmentation (more generally, model prediction) task where advanced topics are addressed. Particularly, in this notebook we demonstrate how a user can use TIAToolbox to solve the problems in the following three scenarios: - 1. Instead of pretrained models embedded in TIAToolbox repository, user wants to use their your own deep learning model (in PyTorch) using the TIAToolbox prediction workflow. - 2. User's input data is of an exotic form which the TIAToolbox data stream functionality does not support by default.
- Corrections and bug fixes for example notebooks 5 and 6. - Small changes have been made to make these two notebook aligned with the new model APIs, adding explanations for the new arguments, correcting TIAToolbox name, correct for spelling and grammar errors, etc. Co-authored by: @mostafajahanifar
- Add cli for nucleus instance segmentation - Add tests for cli and remove tests if cli is covering these. - Fix link for pretrained models in semantic segmentation - Rearrange add commands in cli - Replace `get_wsireader` with `WSIReader.open` as `get_wsireader` is being depreciated. - Update installation instructions for pygeos. - Fix OOM errors using garbage collection `gc.collect()`. Co-authored by: @shaneahmed
- Add classes which can generate zoomify tiles from a WSIReader object.
Example
--------
```python
from tiatoolbox.wsicore.wsireader import WSReader
from tiatoolbox.tool.pyramid import ZoomifyGenerator
wsi = WSReader.open("slide.svs")
zoomify_gen = ZoomifyGenerator(wsi) # Defaults to 256x256 tiles
tile = zoomify_gen.get_tile(0, 0, 0) # PIL Image
```
Co-authored-by: @John-P
- Add classes and functions under `tiatoolbox.tools.graph` to enable construction of graphs in a format which can be used with PyG (PyTorch Geometric).
… to StainAugmentor (#197) - Change class names to fit in line with the rest of the API. Namely, we change: - `CNNPatchPredictor` -> `PatchPredictor` - `StainAugmentation` -> `StainAugmentor` Co-authored-by: @simongraham
- Add classes which act as a mutable mapping (dictionary like) structure and enables efficient management of annotations. An annotation here is defined as a geometry and some associated JSON data. Currently, supported features are:
- A common interface for multiple backends:
- SQLite (with an rtree index for fast spatial queries)
- Pure Python dict (stored as geoJSON on disk)
- Serialisation and deserialisation to and from disk
- Compression (SQLite only)
- Conversion to and from other formats:
- geoJSON
- JSON Lines / ndjson
- Pandas dataframe
- Spatial queries using a bounding box or shapely Polygon
- Customisable binary shape predicate (defaults to intersection)
- Query predicates on properties using:
- A subset of python (fastest, compatible across backends with some limitations)
- A pickled function
- A python callable (slowest but easiest and can be any Python code)
- Custom indexes (SQLite only) for accelerated queries
Example (`SQLiteStore`)
-------------------------
```python
from shapely.geometry import Polygon
from tiatoolbox.annotation.storage import SQLiteStore, Annotation
store = SQLiteStore("polygons.db")
# Create a test geometry (polygon, point, or line string)
triangle = Polygon([(0, 0), (1, 1), (0, 2)])
# Store an annotation geometry with a class label
key = store.append(Annotation(triangle, {"class": 1}))
# The value returned in a unique key (UUID4 by default)
# Get the stored annotation (tuple of geometry and properties dict returned)
print(store[index])
# Store an annotation geometry with a custom key
store.append(Annotation(triangle, key="foo"))
print(store["foo"])
# or use __setitem__ syntax:
store[key] = Annotation(triangle)
# Change the properties of an annotation in the store
store.patch(key, {"class": 2})
# Query in a bounding box
results = store.query([0, 0, 128, 128])
# Query using any polygon
results = store.query(Polygon.from_bounds([0, 0, 128, 128]))
# Query in a bounding box but just return only the indexes (rather than the polygons and properties)
# This can be much faster than returning geometries or doing a geometry query
# as the indexes are small and neither the geometries nor the properties have to
# be decoded for the query to run.
results = store.query_index([0, 0, 128, 128])
# Query with a predicate statement
results = store.query([0, 0, 128, 128], where="props['class']==4")
# Create an index (SQLite only)
# Can give significant speedup (100x in some tests) even for simple property access e.g.
key = store.create_index("example_index", "props['class']==4")
```
- [x] Swap to using strings for keys.
- [x] Default to UUID4 if no key given.
- [x] Allow custom string keys.
- [x] Change query shape predicate (via string kwarg).
- [x] Deepsource passing.
- [x] Query predicates.
- [x] Custom indexes.
- [x] Annotation compression (optional, defaults to zlib for sqlite).
- [x] Metadata storage (e.g. compression method, tiatoolbox version)
- [x] Test Coverage > 99%.
- [ ] Grouping during query.
- [x] Use dataclass instead of tuple for annotations?
- [x] Conform to / test Python `MutableMapping` interface
- [x] ABC
- [x] `__getitem__`
- [x] `__setitem__`
- [x] `__delitem__`
- [x] `__iter__`
- [x] `__len__`
- [x] Mixins
- [x] `__contains__`
- [x] `keys`
- [x] `items`
- [x] `values`
- [x] `get`
- [x] `__eq__`
- [x] `__ne__`
- [x] `pop`
- [x] `popitem`
- [x] `clear`
- [x] `update`
- [x] `setdefault`
Co-authored-by: @John-P
- Update instructions in `README.md` for developers. - Add defusedxml as dependency in setup.py. - Update virtual environment name to tiatoolbox-dev. - Update README.md for links. Co-authored by: @shaneahmed
- Increase cognitive complexity limit in setup Co-authored by: @John-P
- Replace pygeos with shapely to resolve the GEO binary installation issue. Co-authored-by: @vqdang
- Rename example notebooks
* Added HoVerNet+ model for the simultaneous semantic segmentation of layers and nuclear instance segmentation/classification. * Added HoVerNet+ model for the simultaneous semantic segmentation of layers and nuclear instance segmentation/classification. * Added HoVerNet+ model for the simultaneous semantic segmentation of layers and nuclear instance segmentation/classification. * Added HoVerNet+ model for the simultaneous semantic segmentation of layers and nuclear instance segmentation/classification. * BUG: Fixed bug in forward * BUG: Fixed bug in forward * BUG: Fixed bug in forward * BUG: Changed name of TP branch * DEV: Including model weight info * DOC: Added to model class docstrings. * DOC: Added to model class docstrings. * BUG: Removed unused imports. * DOC: Added to model class docstrings. * DOC: Added to model class docstrings. * FIX: Removed unnecessary dependencies. * FIX: Removed unnecessary dependencies. * UPD: Changed image used for testing. * UPD: Updated crop_op function.. * UPD: Updated test image. * FIX: Corrected formatting issue. * UPD: Updated unit testing for center_crop_to_shape. * UPD: Added unit testing for blocks. * UPD: Added unit testing for HoVer-Net+ model. * UPD: Added unit testing for HoVer-Net+ model. * UPD: Added unit testing for HoVer-Net+ model. * UPD: Correction to formatting. * UPD: Correction to formatting. * UPD: Updated unit testing. * UPD: Updated HoVer-Net+ unit testing. * UPD: Updated HoVer-Net+ unit testing. * UPD: Updated HoVer-Net+ unit testing. * UPD: Changed HoVer-Net+ to be a subclass of HoVer-Net. * UPD: Changed HoVer-Net+ to be a subclass of HoVer-Net. * UPD: Changed HoVer-Net+ to be a subclass of HoVer-Net. * UPD: Changed HoVer-Net+ to be a subclass of HoVer-Net. * UPD: Updated HoVer-Net+ unit testing. * UPD: Updated HoVer-Net+ and HoVer-Net docstrings. * BUG: Fixed error in formatting. * BUG: Removed repeated function in model utils. * UPD: Removed fast/original mode and extra branch options for HoVer-Net+. * UPD: Removed pred_dict extra branch options for HoVer-Net+. * FIX: Resolved utils.misc conflict. * UPD: Changed some functions to private static methods. * UPD: Changed private static methods to protected statis methods. * UPD: Added test for HoVer-Net+ with semantic segmentor. * UPD: Spelling mistake. * FIX: Added garbage collection to nuclear instance functionality test. * FIX: Updated TIALab to Centre * FIX: Updated TIALab to Centre * UPD: Updated HoVerNet/HoVerNet+ docstrings with Examples. Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Fix spacing around backticked words. - Unhide hidden cells. Change "tail --line 1" to "tail -n 1" Incorporate changes implemented by pre-commit hooks. - Change "tail --line 1" to "tail -n 1". Correct spacing around backticked word. - Rewrite text cell on restarting runtime, and replace non-ascii right-arrow by ampersand encoding. Apply pre-commit hooks.
- Adds feature matching functions for deep feature based registration. Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: John Pocock <[email protected]> Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Add `docs/requirements.txt` to `requirements_dev.txt` Signed-off-by: Shan E Ahmed Raza <[email protected]>
- Fix spacing around backticked words. - Unhide hidden cells. Change "tail --line 1" to "tail -n 1" Incroporate changes implrmented by pre-commit hooks. - Change "tail --line 1" to "tail -n 1". Correct spacing around backticked word. - Rewrite text cell on restarting runtime, and replace non-ascii right-arrow by ampersand encoding. Apply pre-commit hooks. - Unhide hidden cells - Rewrite text cell about restarting runtime under Colab. Replace non-ascii em-dash by " —". Pre-commit hooks. - Redo previous commit more carefully.
- Use `requirements.txt` in `setup.py` Signed-off-by: Shan E Ahmed Raza <[email protected]> Co-authored-by: John Pocock <[email protected]>
- Adds PR adds macOS pip install test cases to the GitHub workflow. Co-authored-by: John Pocock <[email protected]> Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Setup workflow on push as GitHub variables for pull request do not work on push.
- Update citation in README.md and CITATION.cff Co-authored-by: John Pocock <[email protected]>
- Run pip install workflow only on requirements file - Update numpy requirements
- Improve TIAToolbox import using lazy imports. - Improves importing `import tiatoolbox` by 10 times. - This will improve execution of cli. Signed-off-by: Shan E Ahmed Raza <[email protected]> Co-authored-by: John Pocock <[email protected]>
The file 09-multi-task-segmentation.ipynb in branch doc-09 is the result of an overnight run on my Macbook, with ON_GPU=False. After the run, I changed this to the default ON_GPU=True. The colour bar shows the background as black. However, I think the background looks grey, so I think this may be a bug, but I'm not sure. The colour bar is produced by tiatoolbox.visualization.overlay_prediction_mask, which has been worked on recently by @Srijay-lab and, perhaps, by @measty.
- Fixed circular import `wsireader` using lazy loading. Signed-off-by: Shan E Ahmed Raza <[email protected]> Co-authored-by: John Pocock <[email protected]>
- Remove nbsphinx and replace it with myst-nb. - Replace Example gallery with examples/README.md. - Remove repetitive jupyter notebook cells from docs. - Hide outputs related to progress bar. - Remove nbsphinx from requirements. - Add myst-nb in requirements. https://tia-toolbox.readthedocs.io/en/dev-doc-use-myst-nb/ Signed-off-by: Shan E Ahmed Raza <[email protected]> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: David Epstein <[email protected]> Co-authored-by: John Pocock <[email protected]> Co-authored-by: vqdang <[email protected]>
updates: - [github.com/psf/black: 22.8.0 → 22.10.0](psf/black@22.8.0...22.10.0) Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
To-do-list: - [x] DFBR on tissue - [x] Excluding matching points that lie outside tissue boundary - [x] DFBR on prealigned tissue sections in a blockwise manner Co-authored-by: Ruqayya Awan <[email protected]> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: John Pocock <[email protected]> Co-authored-by: Shan E Ahmed Raza <[email protected]>
This PR adds support for reading MPP metadata from v0.4 NGFF which was missing. It currently only supports units in micrometers and will use the first scale transform in the axis `coordainteTransformations` list in `.zattrs`. ## To-Do - [x] Unit test coverage Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Shan E Ahmed Raza <[email protected]>
This PR fixes a bug #452 raised by @rogertrullo where only the numerator of the TIFF resolution tags was being read. Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Adds some enhancements to storage.py that are useful when using an AnnotationStore for visualization purposes. Main changes: Support for adding annotations from a hovernet-style .dat through a utility function Addition of 'area' field to table in SQliteStore. Annotations are returned sorted by area, and supports querying for annotations satisfying an area threshold, useful for zoomed-out rendering where annotations which are too small to display can be excluded. After the discussions in tiatoolbox meeting, functions are added to allow to add/remove the area column to save space if its not expected to be needed. Sorting annotations efficiently by area (can create an index on it) allows to effficiently deal with potentially overlapping annotations by drawing geometries of smallest area last. Eg Unsorted rendering: 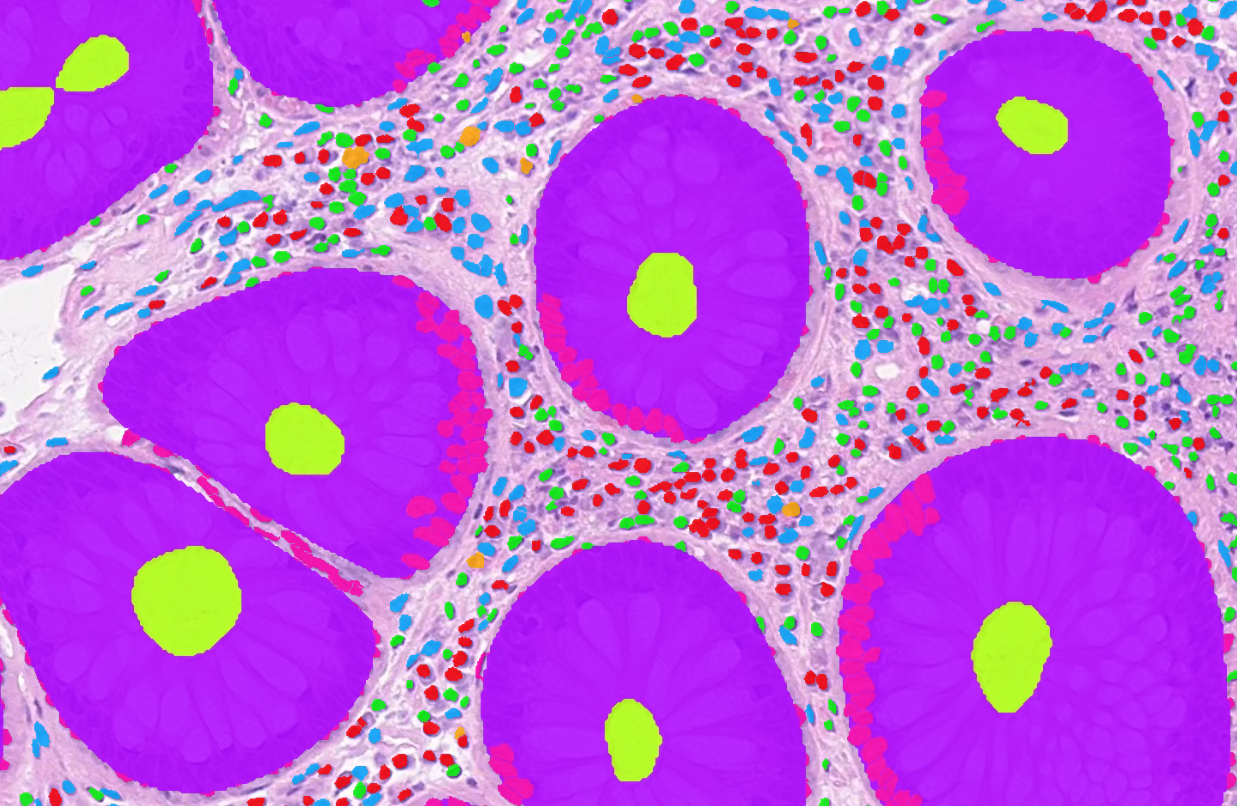 Sorted rendering: 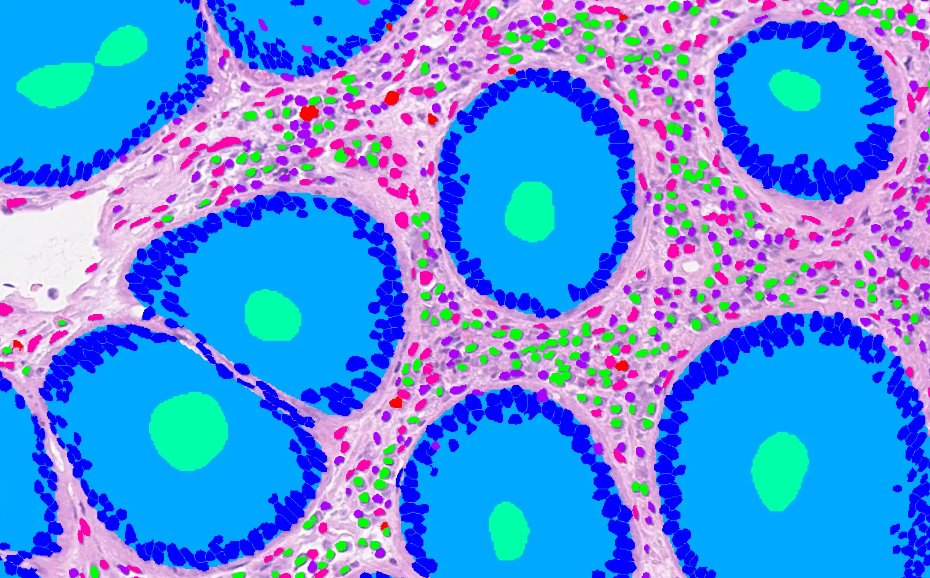 ~~Addition of cacheable versions of query, bquery. The intention with these is to potentially be more efficient when viewing the same area of screen and modifying various options controlling how annotations are rendered (perhaps changing color mapping, or deselecting objects of specific types to be renderered). As in these cases we are displaying the same annotations just in a different way, we dont need to re-load all the annotations for each tile from the store; we can just load the cached annotations and then filter/render them differently. Still needs a bit of testing to see how much this actually helps/if its worth using~~ (caching aspects of the PR removed for now after feedback, may revisit this later in a separate PR) Co-authored-by: John Pocock <[email protected]> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Shan E Ahmed Raza <[email protected]>
{kind=link}
{kind=link}
- Estimation of BSpline transform - Applying estimated transform on the moving image Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: John Pocock <[email protected]> Co-authored-by: Shan E Ahmed Raza <[email protected]>
Notebook to show how to perform WSI registration using the DFBR method, followed by the BSpline approach. Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: David Epstein <[email protected]> Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Fix an issue with the HoVer-Net+ post-processing. Previously, a simple blur was applied for the post-processing. Now it is updated inline with the original work - using various morphological operations specific to each epithelial layer. - Remove warnings from importing specific libraries in both HoVer-Net and HoVer-Net+. Co-authored-by: Shan E Ahmed Raza <[email protected]>
- Refactor the code for parsing OME-TIFF metadata - Fix a bug where an exception would be raised if the OME XML is missing objective power. This was noticeable when there was MPP data but not objective power such as with file created by tifffile. Co-authored-by: Shan E Ahmed Raza <[email protected]> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
### Major Updates and Feature Improvements - Adds an AnnotationTileGenerator and AnnotationRenderer which allows serving of tiles rendered directly from an annotation store. - Adds [DFBR](https://arxiv.org/abs/2202.09971) registration model and jupyter notebook example - Adds DICE metric - Adds [SCCNN](https://doi.org/10.1109/tmi.2016.2525803) architecture. \[[read the docs](https://tia-toolbox.readthedocs.io/en/develop/_autosummary/tiatoolbox.models.architecture.sccnn.SCCNN.html)\] - Adds [MapDe](https://arxiv.org/abs/1806.06970) architecture. \[[read the docs](https://tia-toolbox.readthedocs.io/en/develop/_autosummary/tiatoolbox.models.architecture.mapde.MapDe.html)\] - Adds support for reading MPP metadata from NGFF v0.4 - Adds enhancements to tiatoolbox.annotation.storage that are useful when using an AnnotationStore for visualization purposes. ### Changes to API - None ### Bug Fixes and Other Changes - Fixes colorbar_params #410 - Fixes Jupyter notebooks for better read the docs rendering - Fixes typos, metadata and links - Fixes nucleus_segmentor_engine for boundary artefacts - Fixes the colorbar cropping in tests - Adds citation in README.md and CITATION.cff to Nature Communications Medicine paper - Fixes a bug #452 raised by @rogertrullo where only the numerator of the TIFF resolution tags was being read. - Fixes HoVer-Net+ post-processing to be inline with original work. - Fixes a bug where an exception would be raised if the OME XML is missing objective power. ### Development related changes - Uses Furo theme for readthedocs - Replaces nbgallery and nbsphinx with myst-nb for jupyter notebook rendering - Uses myst for markdown parsing - Uses requirements.txt to define dependencies for requirements consistency - Adds notebook AST pre-commit hook - Adds check to validate python examples in the code - Adds check to resolve imports - Fixes an error in a docstring which triggered the failing test. - Adds pre-commit hooks to format markdown and notebook markdown - Adds pip install workflow to resolve dependencies when requirements file is updated - Improves tiatoolbox import using LazyLoader Signed-off-by: Shan E Ahmed Raza <[email protected]>
|
Check out this pull request on See visual diffs & provide feedback on Jupyter Notebooks. Powered by ReviewNB |
Codecov Report
@@ Coverage Diff @@
## master #496 +/- ##
==========================================
+ Coverage 99.60% 99.63% +0.02%
==========================================
Files 55 61 +6
Lines 5358 6240 +882
Branches 960 1035 +75
==========================================
+ Hits 5337 6217 +880
- Misses 9 10 +1
- Partials 12 13 +1
📣 We’re building smart automated test selection to slash your CI/CD build times. Learn more |
…string (#497) - Fix FLK-D202 No blank lines allowed after function docstring - Update README.md for badge location
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Major Updates and Feature Improvements
Changes to API
Bug Fixes and Other Changes
Development related changes