This repository contains the official implementation for "SlimDoc: Lightweight Distillation of Document Transformer Models," published in the International Journal on Document Analysis and Recognition (IJDAR), 2025.
Abstract from the paper is as follows:
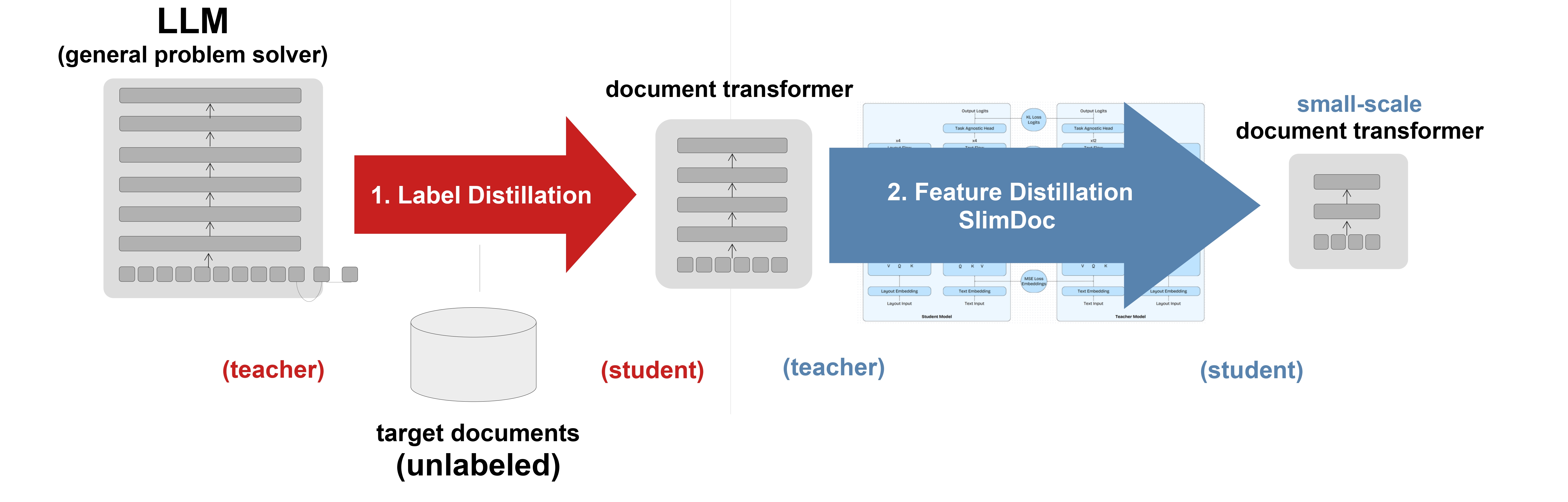
Deploying state-of-the-art document understanding models remains resource-intensive and impractical in many real-world scenarios, particularly where labeled data is scarce and computational budgets are constrained. To address these challenges, this work proposes a novel approach towards parameter-efficient document understanding models capable of adapting to specific tasks and document types without the need for labeled data. Specifically, we propose an approach coined SlimDoc to distill multimodal document transformer encoder models into smaller student models, using internal signals at different training stages, followed by external signals. Our approach is inspired by TinyBERT and adapted to the domain of document understanding transformers. We demonstrate SlimDoc to outperform both a single-stage distillation and a direct fine-tuning of the student. Experimental results across six document understanding datasets demonstrate our approach’s effectiveness: Our distilled student models achieve on average 93.0% of the teacher’s performance, while the fine-tuned students achieve 87.0% of the teacher’s performance. Without requiring any labeled data, we create a compact student which achieves 96.0% of the performance of its supervised-distilled counterpart and 86.2% of the performance of a supervised-fine-tuned teacher model. We demonstrate our distillation approach to pick up on document geometry and to be effective on the two popular document understanding models LiLT and LayoutLMv3.
The repository supports the following models out of the box:
Download from Google Drive. It includes:
- Datasets:
- Extractive VQA subsets for the first three datasets
- LAPDoc prompts and results for the unsupervised transitive distillation
- Small/tiny vocab files for student models
Install dependencies:
pip install -e .Required packages: torch, transformers, tqdm, Levenshtein, wandb, pandas, jsonlines, pdf2image, datasets
Then, place the downloaded data folders into slimdoc/data.
Training
Run with -h for full CLI help:
train/train.py: fine-tune or distill a single modeltrain/runner.py: batch fine-tune/distill (e.g., all 4-layer students)
Evaluation
python eval/eval.py [RUN_NAME]For DocVQA, InfographicsVQA, and WikiTableQuestions evaluations, install DUE benchmark evaluator.
@article{Lamott_Shakir_Ulges_Weweler_Shafait_2025a,
title={SlimDoc: Lightweight distillation of document Transformer models},
DOI={10.1007/s10032-025-00542-w},
journal={International Journal on Document Analysis and Recognition (IJDAR)},
author={Lamott, Marcel and Shakir, Muhammad Armaghan and Ulges, Adrian and Weweler, Yves-Noel and Shafait, Faisal},
year={2025},
month={Jun}
}