Initial utility collections docs #110
Conversation
807fb09 to
4585b77
Compare
 vmx
left a comment
vmx
left a comment
There was a problem hiding this comment.
Great write-up.
A general note (not really specific to this PR). Could we use lowercase directories/filenames? That makes things on the terminal on case-sensitive systems way easier :)
|
|
||
| Collections are a fundamental primitive in every programming language. Being able to organize data into collections that allow for convenient and efficient access and modification is a core activity in programming. | ||
|
|
||
| While IPLD is not a programming languagelement, indext represents enormous potential for sharing data and providing access to diverse and very large data sets. With sufficient data organization primitives, IPLD can replace many functions traditionally provided by a centralized database system. Client applications should be able to access and even manipulate data structures stored across many peers, from trivial lists to massive and complex data sets that are exposed with efficient query and search operations. |
There was a problem hiding this comment.
First sentence has typos and I can't really make sense of it.
| * `Remove(element)` | ||
| * `Iterate()` | ||
| * `Contains(element)?` | ||
| * `Size()?` |
There was a problem hiding this comment.
I’m always concerned when we encode information like this into the root node, because you could just lie ;)
Without traversing the entire structure you don’t actually know the real size. For instance, we encode the length of files into unixfs-v2 but it can’t really be trusted. It’s useful in interfaces for showing “this file/directory is {size}” without actually requesting all the blocks, but I’m constantly worried people will trust it when they shouldn’t.
If we put a size property in the base interface I’m concerned that it will lead people to trust it, and it’s actually very easy to lie.
There was a problem hiding this comment.
I don't think that's built into this document though, I'm leaving that open to the implementation and just listing this as a possible operation. In fact, I was just assuming here that it would be implemented as an actual traversal calculation if it's implemented at all. It's what I did in iamap but the user has to know the cost of calling it!
README.md
Outdated
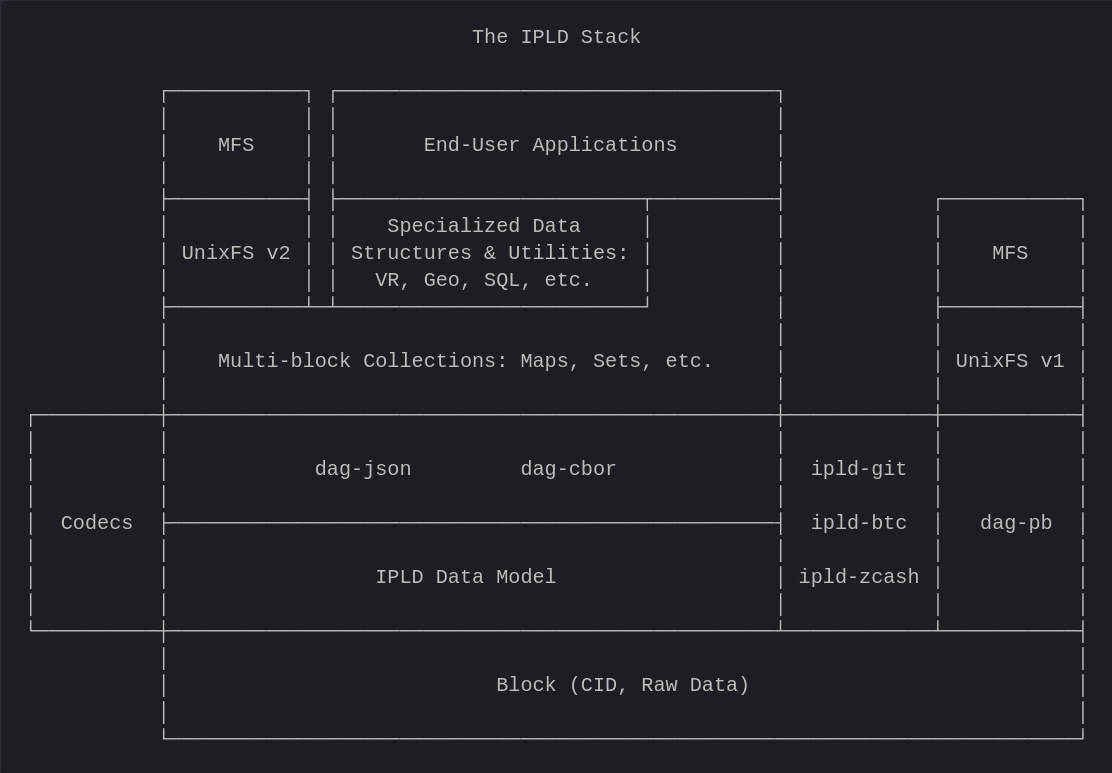
| │ MFS │ │ End-User Applications │ | ||
| │ │ │ │ | ||
| ├───────────┤ ├─────────────────┬──────────────────┤ ┌───────────┐ | ||
| │ │ │ Structured Data │ Utility │ │ │ |
There was a problem hiding this comment.
“Utility Collections” should actually just replace “Complex Data Structures.” unixfs relies on hamt which is a collection, and there’s no way you can make SQL and GeoSpatial interfaces without these as well.
There was a problem hiding this comment.
I think I need to understand the geo etc. stuff better. I'm thinking the name "Specialized Data Structures" might be more suited and maybe "End-User Applications" should wrap around it so it's still also sitting on "Utility Collections".
So, I get GeoSpatial, but I don't know what "VR" is referring to in this context and I'm not sure "SQL" makes sense under that heading because it's an interfacing method rather than a collection type. @mikeal can you expand on the thoughts behind this category a bit?
There was a problem hiding this comment.
I agree with @rvagg version here. That's also my view on things. The old version was wrong anyway. A Geo index is not a sorted index.
|
oh, I've just worked out why some of the words are jumbled up -- before pushing this i did a replace of variable names I used in the methods, they were like this: |
42a715d to
ce6cb1c
Compare
|
Re the floor/ceil thing: it was supposed to be implicit and it's really up to the collection implementor to decide on the reasons for exposing things in different ways. I've added this paragraph as well as some clarifying notes in the sorted collections:
The same thing goes for Re the block diagrams: I've rejiggered it again in a way that I think reflects the ideal reality. "Utility Collections" sits underneath them all, I've renamed that other block to "Specialized Data Structures & Utilities: VR, Geo, SQL, etc.". GeoSpacial will be more about data structures I think but SQL will be more about utilities on top of the base collections. That's where the interesting ecosystem of specialized use-cases will evolve and things will get really interesting! |
I would add "Maps, Sets, etc." back to "Utility Collections", at least to me it makes things clearer. |
|
I think this is OK to land, aside from the "Map" and "List" naming conflicts discussed in #112 (comment) which I wouldn't mind clearing up a little. |
|
In an attempt to deal with the "Map" and "List" confusion with the data model, I've tried the following:
Here's what the stack looks like:
Does that help or just make it more confusing? |
50050b5 to
fb16d49
Compare
|
I'd like to merge this, does anyone have objections? It's not a "spec" per se, more of an introduction to specs that will hopefully fill this directory. |
We have a bunch of those so that shouldn’t be a blocker. An action item I have for us to talk through at the summit is some kind of staging process for specs so that we can clearly communicate the state and intention of different specs as we are currently documenting things that are not implemented, being implemented, and even things that are fully implemented that we are actively seeking to move away from. So, spec activity and newness is not a very useful signal and we’ll need to find something more explicit. Anyway, +1 to merge. |
Rework the operation.md doc a bit
Initial utility collections docs
This is a WIP and I'm mainly interested in feedback from folks who have been thinking about this stuff longer than me.
I've done a few things here:
/cc @mikeal @vmx @warpfork - who else?