Add Span.Reverse() intrinsic for Arm64 #72780
Conversation
|
I couldn't figure out the best area label to add to this PR. If you have write-permissions please help me learn by adding exactly one area label. |
c48606f to
3d4cc3f
Compare
src/libraries/System.Private.CoreLib/src/System/Runtime/Intrinsics/Vector128.cs
Outdated
Show resolved
Hide resolved
3d4cc3f to
aee62fe
Compare
|
The new version of the patch removes changes from Base64Encoder/Base64Decoder to use |
aee62fe to
c673a31
Compare
|
Debugging test failures. Unfortunately, the failures are not reproducing locally. |
|
@dotnet/jit-contrib |
| tempLast = Avx2.Shuffle(tempLast, reverseMask); | ||
| tempLast = Avx2.Permute2x128(tempLast, tempLast, 0b00_01); | ||
| tempFirst = Vector256.Shuffle(tempFirst, Vector256.Create(15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0)); | ||
| tempLast = Vector256.Shuffle(tempLast, Vector256.Create(15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0)); |
There was a problem hiding this comment.
@SwapnilGaikwad I was able to reproduce the test failure you observe, they're fixed if I change Vector256.Shuffle to Avx2.Shuffle
There was a problem hiding this comment.
Thanks @EgorBo, I will rollback changes to AVX2 and update the patch.
There was a problem hiding this comment.
This is likely due to Vector256.Shuffle being 1x256 op rather than 2x128 ops (Avx2.Shuffle is the latter).
You generally need to offset the counts of the upper elements by Vector128<T>.Count to ensure the operation works as expected.
There was a problem hiding this comment.
Just to confirm, is there any reason to not continue using reverseMask that is created once outside the loop instead of using Vector256.Create()? It should get hoisted outside the loop, but can you double check?
There was a problem hiding this comment.
Because for .NET 7 the Shuffle check for "is this a constant" happens in import only and so constant prop and other bits won't have happened yet and the import as intrinsic will fail.
This is something I want to fix early for .NET 8.
There was a problem hiding this comment.
This is something I want to fix early for .NET 8.
So until that happens, we should hoist those creations manually outside the loop?
There was a problem hiding this comment.
I am specifically referring to Vector256.Create(15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0) part.
There was a problem hiding this comment.
No, the point is we should not hoist them because that will break intrinsic recognition for Vector256.Shuffle. We explicitly want the intrinsic recognition to happen and then the JIT will CSE the constant and hoist it itself.
There was a problem hiding this comment.
Ah I see what you are saying.
You can try replicating the failures using the exact binaries that were run in CI. For that, you need runfo tool to download the payload. Here are the instructions to replicate e.g. these failures, which I was able to reproduce on my windows-x64 modern hardware machine. Let us know if you still have trouble reproing the failures. |
| { | ||
| ref byte bufByte = ref Unsafe.As<char, byte>(ref buf); | ||
| nuint byteLength = length * sizeof(char); | ||
| Vector256<byte> reverseMask = Vector256.Create( |
There was a problem hiding this comment.
The issue with when you tried to replace Avx2.Shuffle with Vector256.Shuffle is that you didn't adjust the reverseMask.
You should change this:
Vector256.Create(
(byte)15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, // first 128-bit lane
15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0)); // second 128-bit laneTo:
Vector256.Create(
(byte)15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0, // first 128-bit lane
31, 30, 29, 28, 27 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16)); // second 128-bit laneThe Vector256 APIs operate as if it is 1x256-bit vector rather than as 2x128-bit vector lanes. This is consistent with how AVX-512, Arm64, WASM, Vector64, Vector128, and other types all operate.
There was a problem hiding this comment.
If you do this, then Vector256.Shuffle(tempFirst, Vector256.Create(...)) will work as expected and still be performant on AVX2 hardware where you don't want to cross lanes.
There was a problem hiding this comment.
The
Vector256APIs operate as if it is1x256-bitvector
In this case, shouldn't we adjust the mask to
Vector256.Create(
(byte)31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16,
15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0 ));
I noticed the issue the reverse mask but couldn't reproduce the failure yet. Does the runfo tool expects to use Windows only? The steps using runfo to reproduce the pipeline failure seem create a batch file to run on Windows.
There was a problem hiding this comment.
runfo
It can be used on Linux as well. You just need to pass the right job-id and work item which you can find it in AzDo.
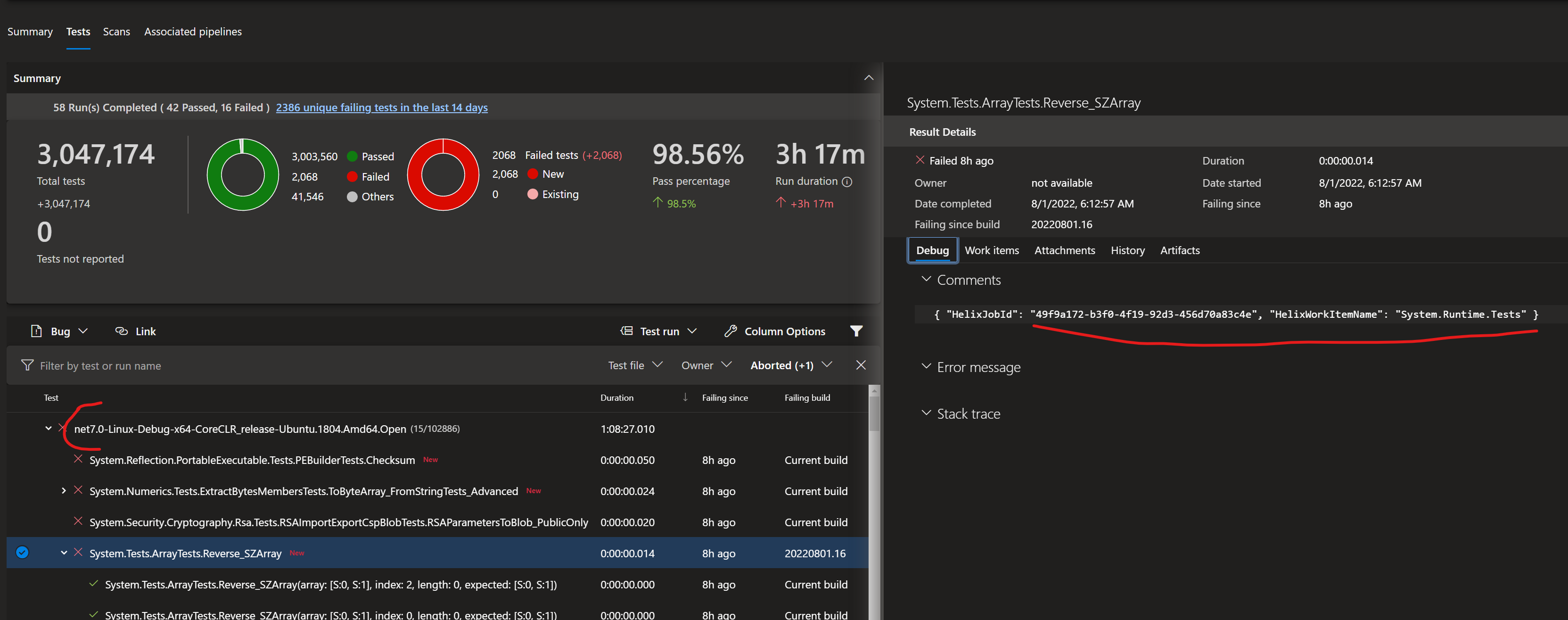
The RunTests.cmd/sh is present in the zip folder you download.
There was a problem hiding this comment.
ooh, right. Thanks Kunal.
There was a problem hiding this comment.
Can we leave the AVX2 changes out of this patch. The patch is now self contained to changes in the 128bit variants.
I'm happy for 256bit part to be changed if it's obvious, but clearly it's going to require some extra debugging to get right and not break performance (given #72793). Let's avoid feature creeping this PR.
There was a problem hiding this comment.
I think it's fine to leave it untouched, crossplatform Vector256 apis are mostly for consistency, they're not crossplatform and unlikely to be ever so
|
I don't think there are any outstanding review comments on this patch ? (The CI failures just look like timeouts?) |
 adamsitnik
left a comment
adamsitnik
left a comment
There was a problem hiding this comment.
It looks great to me! Big thanks for your contribution @SwapnilGaikwad !
I have provided four minor suggestions. I am going to apply them now so we can merge the PR today. I hope you don't mind.
src/libraries/System.Private.CoreLib/src/System/SpanHelpers.Byte.cs
Outdated
Show resolved
Hide resolved
src/libraries/System.Private.CoreLib/src/System/SpanHelpers.Char.cs
Outdated
Show resolved
Hide resolved
| Array arrayClone2 = (Array)array.Clone(); | ||
| Array.Reverse(arrayClone2, index, length); | ||
| Assert.Equal(expected, expected); | ||
| Assert.Equal(expected, arrayClone2); |
| { | ||
| // SByte | ||
| yield return new object[] { new sbyte[] { 1, 2, 3, 4, 5 }, 0, 5, new sbyte[] { 5, 4, 3, 2, 1 } }; | ||
| yield return new object[] { new sbyte[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65 }, 0, 65, new sbyte[] { 65, 64, 63, 62, 61, 60, 59, 58, 57, 56, 55, 54, 53, 52, 51, 50, 49, 48, 47, 46, 45, 44, 43, 42, 41, 40, 39, 38, 37, 36, 35, 34, 33, 32, 31, 30, 29, 28, 27, 26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1 } }; |
There was a problem hiding this comment.
thank you for adding a lot of new test cases!
|
Tagging subscribers to this area: @dotnet/area-system-memory Issue DetailsThis patch adds SIMD implementation of Span.Reverse() for Arm64. It improves performance on Arm64 (speedup ~8x for Bytes, ~4.5x for Chars, ~2x for Int32). There is no noticeable performance difference observed on x86. Arm64 (Altra): x86 (Xeon Gold 5120T):
|
|
Thanks a lot @adamsitnik for pushing this PR further 👍 |
 kunalspathak
left a comment
kunalspathak
left a comment
There was a problem hiding this comment.
LGTM. Thanks for your contribution.
|
The failure is unrelated (#73668), merging! |
|
Improvements dotnet/perf-autofiling-issues#7374 |
This patch adds SIMD implementation of Span.Reverse() for Arm64. It improves performance on Arm64 (speedup ~8x for Bytes, ~4.5x for Chars, ~2x for Int32). There is no noticeable performance difference observed on x86.
Arm64 (Altra):
x86 (Xeon Gold 5120T):