SqlClient reduce lock contention #37157
Conversation
|
Am a total outsider to SqlClient, so take the following with a very large grain of salt:
|
|
One additional issue with this PR: _connectionPoolGroups is also accessed from PruneConnectionPoolGroups(), which hasn't been modified and continues to lock |
When you get this contention is startup going from no new connections to as many as you can and this lock is what prevents every connection through that pool until it's been created. Allowing every caller to try and setup a pool and letting the first assigner win would spin up huge numbers of connections so you really do need the lock but I've tried to minimize what's done under it. You're right on the connection groups assignment, the lock was providing a barrier and I've neglected to add one. I've changed it to use Interlocked for the assignment. |
|
@Wraith2 so this is about going from zero connections to one connection? Because it seems like once the pool group is created for a given key we'd never go through that code again? Regarding doing CAS (or ConcurrentDictionary), are you saying that the creation of the DbConnectionPoolGroup itself creates connections, i.e. that we should avoid instantiating DbConnectionPoolGroup and throwing them away? BTW my previous comment about the race condition was wrong, since the assignment occurs within the lock, so the change does get propagated. I'm not 100% sure about ReadWriteLockSlim, so making sure is a good idea. |
Exploring the code a bit, I don't see any issue with a CAS loop which would create a new DbConnectionPoolGroup and possibly throw it away:
Other than that nothing actually seems to be happening... |
You can't use CompareExchange on this because you can't get a ref to the internals of the dictionary. ConcurrentDictionary is pretty well optimized so I'm not too worried about it's perf, it'll be fast if it can.
The prune call does still lock but only with itself and if you're hitting prune you're not at high contention on that pool because something in it has been allowed to sit idle for long enough to be pruned. |
|
@Wraith2 I admit I haven't looked at DbConnectionPoolGroup.GetConnectionPool or the changes you made to it (I haven't had time). I'm only referring to DbConnectionFactory.GetConnectionPoolGroup.
Well, this specific dictionary is private, so relatively limited in scope and safer to refactor. I'd need to look more in-depth tomorrow, but at this point I can't really see any reason not to replace
The point is that before your PR, both prune and GetConnectionPoolGroup() locked on this (so could not run concurrently). Your PR changes GetConnectionPoolGroup() to use a different locking mechanism, but leaves prune as-is, so both these methods can now execute concurrently and interfere with one another. For example, pruning could start copying the dictionary just as GetConnectionPoolGroup() is adding a new pool group, which would be missed by prune and therefore forgotten when it assigns the new dictionary. |
No, I changed prune to use the same reader writer lock so they're still mutually exclusive in the same region they were before but now there can be multiple readers in a section where only one was allowed before and the lock is escalated if an assignment is needed, which is rare. |
Sorry, my bad! I somehow missed the change in prune, reading code late at night can lead to that... I'll try to have another look at the the two types tomorrow and see what I can figure out. |
|
There is indeed a Prune as well in DbConnectionPoolGroup.cs which uses a lock. I wonder if the confusion arose from that vs PruneConnectionPoolGroups that @Wraith2 actually changed. |
|
I looked at this again with fresh eyes, and would like to come back to what I wrote above:
So this optimization only affects the very first call, when a pool doesn't yet exist for the given pool key (and user identity) - so it would have no effect whatsoever on application steady performance. In addition, from what I can tell, time spent within these locks is quite negligible - no actual connections are being created (only DbConnectionPoolGroup and DbConnectionPool), and no I/O is being performed. @Wraith2, am I correct to assume that the DotTrace snapshots you posted above are the result of a run opening a single connection? In other words, your test scenario doesn't perform any iterations opening many connections? Assuming I haven't grossly misunderstood things, it doesn't seem like this code specifically is worth optimizing - it will typically execute once in the application's lifetime (modulu pruning, which should also be rare), and we wouldn't see any actual effect on perf. We should instead concentrate on the hot path, where all the pooling data structures already exist, and a connection is being allocated (and returned!) to the pool. It may be worth refactoring this code to simplify it - as I wrote above, it seems over-engineered and overly-complex for what it's doing. On the other hand, it's also working well and maybe it's better to just leave it alone. |
All my numbers are from DataAccessPerformance 64 threads (on 16 cores, so 4x contention) for 60 seconds. I'm assuming the contention is all at the start and will affect time to first query because as you say I can't see why any of this would contend once the pools and groups are setup.
I was thinking about this last night and I have a theory. I suspect that the person that wrote it was an sql server internals expert and that what they've implemented is equivalent to an online index rebuild. It takes a copy of the data works on it and then does an atomic replace to ensure that the offline/lock time is minimized. As I mentioned elsewhere this is the horror of the pooling code. It's all like this. There are gains to be had but it's very hard to see them and reason about their efficacy or safety. In general I agree with you that if it isn't a clear benefit then it should be left alone. So the changes in |
Can you share a benchmark that demonstrates a measurable throughput win? |
If I'm reading the code correctly, in the fast path (once everything is set up) the first @stephentoub do we have any infrastructure for doing BDN in corefx? I can't find anything in particular, it would help grealy in cases such as this. |
We have the whole dotnet/performance repo for exactly this purpose. |
|
@stephentoub OK, thanks - was vaguely aware of it, will investigate and see with @Wraith2 what can be done for SqlClient. |
|
Oh great - there's a feature for running a locally-built corefx, perfect. @Wraith2, so as part of any optimization work, it would be ideal to add a benchmark into https://github.com/dotnet/performance/tree/master/src/benchmarks/micro/corefx (creating a System.Data.SqlClient there), which demonstrates exactly what it is we're trying to optimize. Then we'd be able to see (and show) before and after results for the change, justifying it. I'll be happy to assist you if you're new to BenchmarkDotNet (it's really quite good). |
I've got local numbers that show a measurable but not very significant throughput increase of ~0.8%, but I'm not supposed to share them publicly because of sql server license conditions. The scale at which these changes are going to make a useful difference aren't something I can recreate sensibly on a single machine. |
@Wraith2 if data access benchmark is run to measure TPS after SQlClient has warmed up the connection pool with a few connections, will there still be any benefit from this PR? |
|
I've got the timeline profiler api integrated now so I can exclude the warmup (which was 3s all along). And no, Steady state contention is 60ms and it's coming from task machinery doing reflection and If you run it on a hardware and contention configuration closer to the TE benchmark you may get different results. |
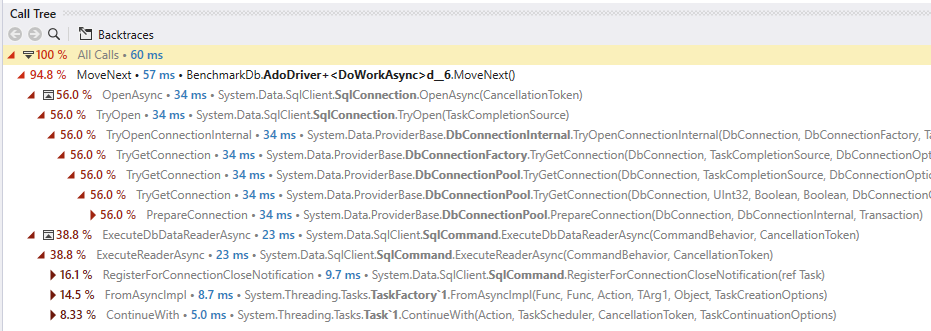
That sounds like a promising direction. It seems that the lock is taken in DbConnectionPool.PrepareConnection to "prevent race conditions with Clear and ReclaimEmancipatedObjects" (PostPop). I'm guessing that a more general refactor is needed of how Clear/ReclaimEmancipatedObjects actually work, in order to remove the need for locking here - it's a shame to introduce locking contention at pooled open just because a pool clear may be happening at the same time. Obviously any reflection and superfluous Task machinery is also a good target. |
|
I think we're in general agreement that these changes aren't particularly useful other than startup which is a rare occurrence. If so I'll close and have a longer look at the only real issue we've identified which is PrepareConnection. On the topic of benching with BDN. a lot of my previous PR results were based on https://github.com/Wraith2/SqlBench/blob/master/Program.cs which is a project setup for benching and profiling very focussed simple cases. It could be generalised to use any ADO driver and serve as a base to get some ongoing internal numbers from. |
Makes sense to me.
Great that you're already experienced with BDN - I never do any sort of optimization work without a BDN benchmark showing the difference. Npgsql has a BDN suite - not perfect or very comprehensive, but it does benchmark some pretty common scenarios. For example, at some point, when optimizing the open mechanism (including some pooling work) I was working with this trivial benchmark. |
relates to https://github.com/dotnet/corefx/issues/30430 and https://github.com/dotnet/corefx/issues/25132
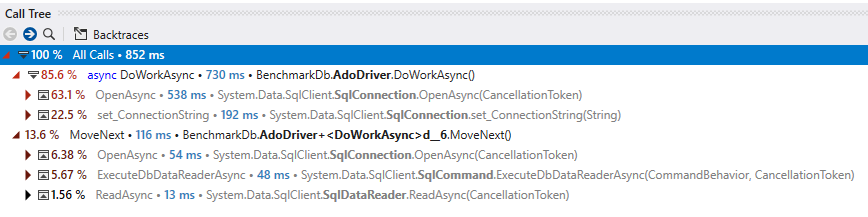
Profiling shows that getting sql connections out of the pool can hit hot locks and potentially limit maximum throughput. I've used the DataAccessPerformance benchmark based on the TechEmpower benchmarks available here to review and make some small changes which roughly halve the contention.
before:
after:
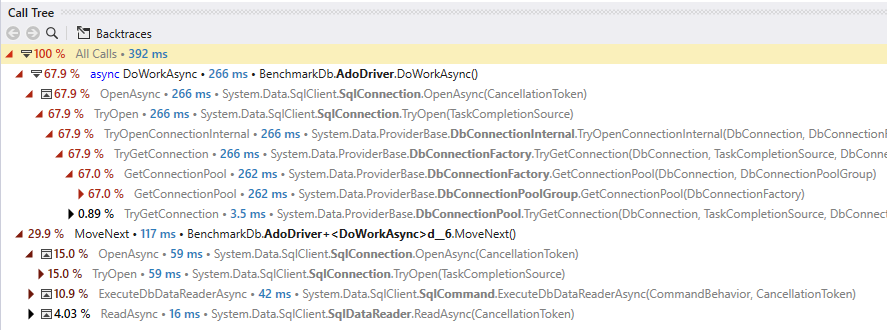
DbConnectionFactoryI changed from using lock to aReaderWriterLockSlimwhich completely eliminates Set_Connection from the contention in this benchmark.Functional manual and load testing with the benchmark all pass without problems. This is all about locking though so please review carefully.
/cc all the area people @afsanehr, @tarikulsabbir, @Gary-Zh , @David-Engel and interested people @saurabh500 @roji