Remove the Either Int from value2term
#87
Conversation
a17f107 to
2d580d2
Compare
|
This sounds very exciting! I'm not too sure which error you are referring to, could you provide an example which triggers it? I'm curious to compare the behaviours, even if this case is rare or non-existent in the wild. Does this have any effect on PGF size? I presume the resulting PGF produced with this modification is different, in the sense that it will have a different md5sum. Has any comparison of old/new PGFs been done with say gftest? |
|
@johnjcamilleri In the old version, where It looks to me that the PGFs are identical. I ran gftest on an application grammar as a part of my normal development process (store old PGF compiled with old GF -> implement new feature -> compile with new GF -> gftest the two versions) and got the expected results, that is, only intended changes. I also linearised manually some ad hoc test sentences on the PGF compiled with the new GF, and was happy with them. |
|
Ah, so this is a GF compilation error we're talking about. If the PGFs have the same md5 they are surely identical, no need to use gftest for that 🙃 |
|
This change should not change the behaviour in any way other than with respect to performance (and possibly error messages), since all I've done is remove the The only ways it could change anything is if some code relies on the error of the |
|
Sounds reasonable, Andreas. I would make the same assumption about it indicating a compiler bug. Since the performance gains are so huge, we should really push this through for inclusion in the next release. But before merging, it would be nice to get the blessing of someone who knows the internals well. Looking at the git history, seems it was @krangelov who introduced the |
|
I finally got around to testing the version of GF, however I'm disappointed to say that I haven't noticed any improvement at all 😞
In both cases I saw identical time and space usage with the old and new GF versions. I'm pretty sure I was not using the same GF executable for both, as I changed the version number in So, any idea why in certain cases this gives no improvement at all? Or maybe I'm doing something wrong? |
|
@johnjcamilleri Building the RGL to GFOs uses The only grammar I've seen with such a dramatic effect is the one I mentioned in the email to you and Aarne on 29th November at 16:23 (DG address). That particular application grammar only compiles to 300 or so concrete categories, so it's very mysterious how come it even took that long before the fix. I have just synced it to DG's repo, so you can easily find the grammar there. As for other grammars, I see mostly differences in memory usage. For example, compiling the French RG into a PGF takes still over 2 minutes, but it never uses more than 700MB memory on my computer. Contrast with the old version, where I start compiling and it's almost immediately at 3GB. I'll try some others to see if I find a clear test that is still shorter than 2 minutes. :-P |
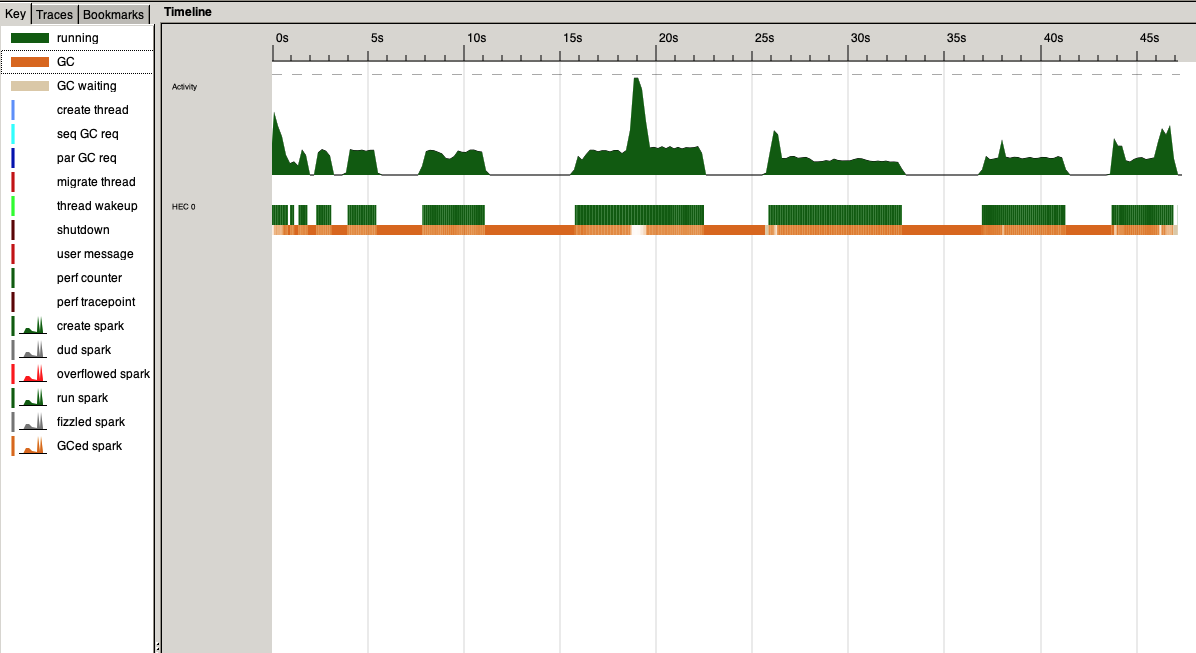
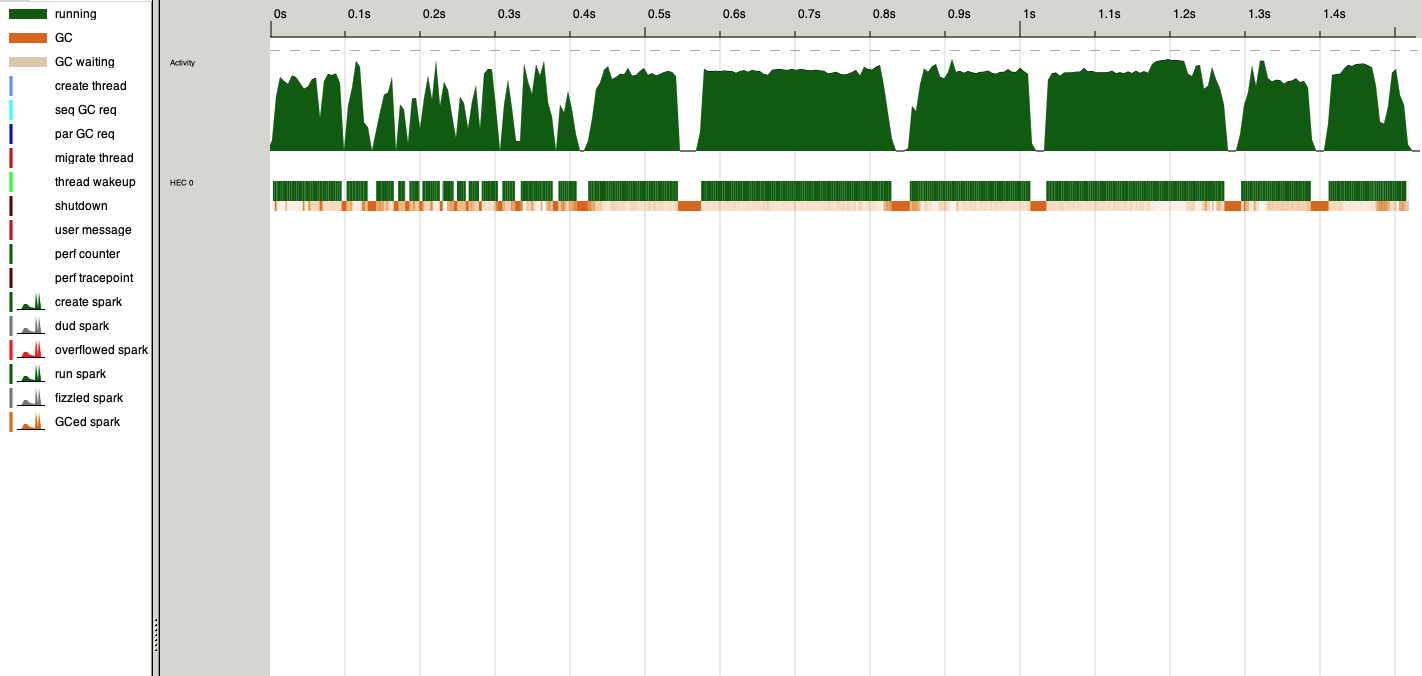
Results for other grammarsHere's a result for the Somali resource grammar: Not a huge difference in time, I agree. I had my activity monitor open, and gf-old-slow used 1.3GB memory, gf used around 400 MB. For Basque RG, the numbers are practically the same, 1.41 GB old vs. 1.37 GB new (tested just once), and both around 24 seconds. Zulu RG has another pattern, where both versions take around 2GB memory for the bulk of the compilation, and a peak at 6-7 GB, but the new version is quite significantly faster: Wild speculation about the nature of the bug and fixSo if the grammar is actually big, the fix isn't doing miracles. (For example, I still don't manage to produce a PGF of Romanian.) But sometimes GF is unreasonably slow for smaller grammars, in a way that genuinely looks like a bug. Looking at graphs, what seems to improve was the time spent on garbage collection. Here's the before, on that anomalous application grammar:
And here's after: So this fix seems to work for an anomalous case. While not as dramatic as we hoped for, it's still an improvement---maybe more accurately described as a bugfix? It's funny that the first grammar on which we tried the fix produced a result of 50GB to 42MB. That certainly coloured our expectations :-P I've been using this new GF for 11 days now, and so far haven't noticed that anything is going worse than it used to. Of course, it would be nice to have guarantees that it didn't cause any new anomalies, like some Foods grammar suddenly taking 10 minutes. |
This prevents HUGE space leak and makes compiling a PGF a LOT faster For example, an application grammar moved from taking over 50GB of ram and taking 5 minutes (most of which is spent on garbage colelction) to taking 1.2 seconds and using 42mb of memory The price we pay is that the "variable #n is out of scope" error is now lazy and will happen when we try to evaluate the term instead of happening when the function returns and allowing the caller to chose how to handle the error. I don't think this should matter in practice, since it's very rare; at least Inari has never encountered it.
This prevents HUGE space leak and makes compiling a PGF a LOT faster
For example, an application grammar moved from taking over 50GB
of ram and taking 5 minutes (most of which is spent on garbage colelction)
to taking 1.2 seconds and using 42mb of memory
The price we pay is that the "variable #n is out of scope" error is now
lazy and will happen when we try to evaluate the term instead of
happening when the function returns and allowing the caller to chose how
to handle the error.
I don't think this should matter in practice, since it's very rare;
at least Inari has never encountered it.