|
| 1 | +# DLRM |
| 2 | +[DLRM](https://arxiv.org/pdf/1906.00091.pdf) is a deep learning-based recommendation model that exploits categorical data for click-through rate (CTR) prediction and rankings. Its model structure is as follows. Based on this structure, this project uses OneFlow distributed deep learning framework to realize training the model in graph mode on the Criteo data set. |
| 3 | +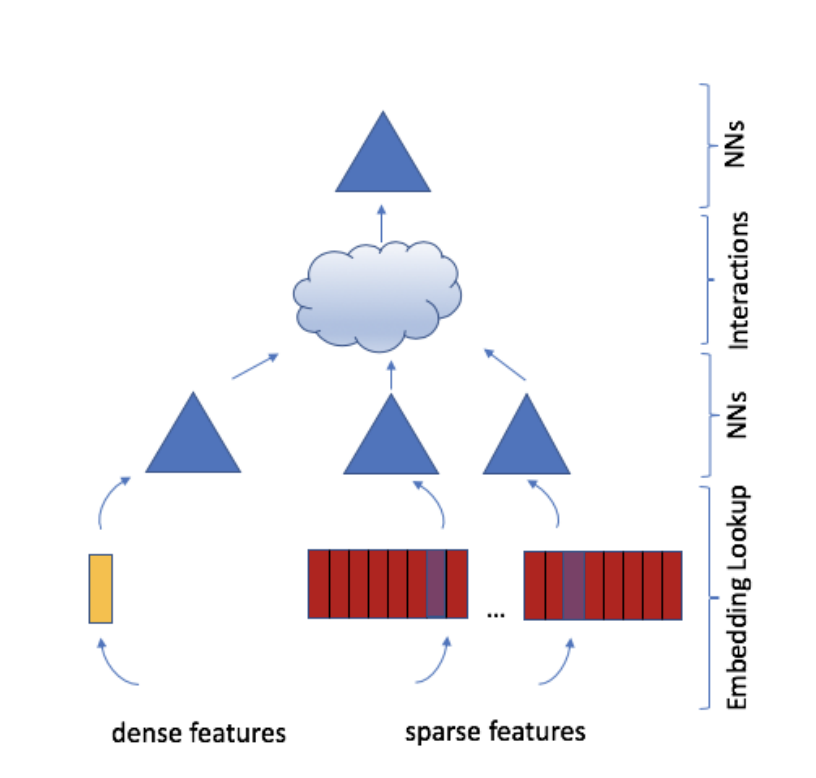 |
| 4 | + |
| 5 | +## Directory description |
| 6 | +``` |
| 7 | +. |
| 8 | +|-- tools |
| 9 | + |-- criteo1t_parquet.py # Read Criteo1T data and export it as parquet data format |
| 10 | +|-- dlrm_train_eval.py # OneFlow DLRM training and evaluation scripts with OneEmbedding module |
| 11 | +|-- requirements.txt # python package configuration file |
| 12 | +└── README.md # Documentation |
| 13 | +``` |
| 14 | + |
| 15 | +## Arguments description |
| 16 | +|Argument Name|Argument Explanation|Default Value| |
| 17 | +|-----|---|------| |
| 18 | +|data_dir|the data file directory|*Required Argument*| |
| 19 | +|persistent_path|path for OneEmbeddig persistent kv store|*Required Argument*| |
| 20 | +|table_size_array|table size array for sparse fields|*Required Argument*| |
| 21 | +|store_type|OneEmbeddig persistent kv store type: `device_mem`, `cached_host_mem` or `cached_ssd` |cached_ssd| |
| 22 | +|cache_memory_budget_mb|size of cache memory budget on each device in megabytes when `store_type` is `cached_host_mem` or `cached_ssd`|8192| |
| 23 | +|embedding_vec_size|embedding vector dimention size|128| |
| 24 | +|bottom_mlp|bottom MLPs hidden units number|512,256,128| |
| 25 | +|top_mlp|top MLPs hidden units number|1024,1024,512,256| |
| 26 | +|disable_interaction_padding|disable interaction output padding or not|False| |
| 27 | +|interaction_itself|interaction itself or not|False| |
| 28 | +|disable_fusedmlp|disable fused MLP or not|False| |
| 29 | +|train_batch_size|training batch size|55296| |
| 30 | +|train_batches|number of minibatch training interations|75000| |
| 31 | +|learning_rate|basic learning rate for training|24| |
| 32 | +|warmup_batches|learning rate warmup batches|2750| |
| 33 | +|decay_start|learning rate decay start iteration|49315| |
| 34 | +|decay_batches|number of learning rate decay iterations|27772| |
| 35 | +|loss_print_interval|training loss print interval|1000| |
| 36 | +|eval_interval|evaluation interval|10000| |
| 37 | +|eval_batches|number of evaluation batches|1612| |
| 38 | +|eval_batch_size|evaluation batch size|55296| |
| 39 | +|model_load_dir|model loading directory|None| |
| 40 | +|model_save_dir|model saving directory|None| |
| 41 | +|save_model_after_each_eval|save model or not after each evaluation|False| |
| 42 | +|save_initial_model|save initial model parameters or not|False| |
| 43 | +|amp|enable Automatic Mixed Precision(AMP) training|False| |
| 44 | +|loss_scale_policy|loss scale policy for AMP training: `static` or `dynamic`|static| |
| 45 | + |
| 46 | +## Getting Started |
| 47 | +If you'd like to quickly train a OneFlow DLRM model, please follow steps below: |
| 48 | +### Installing OneFlow and Dependencies |
| 49 | +To install nightly release of OneFlow with CUDA 11.5 support: |
| 50 | +``` |
| 51 | +python3 -m pip install --pre oneflow -f https://staging.oneflow.info/branch/master/cu115 |
| 52 | +``` |
| 53 | +For more information how to install Oneflow, please refer to [Oneflow Installation Tutorial]( |
| 54 | +https://github.com/Oneflow-Inc/oneflow#install-oneflow). |
| 55 | + |
| 56 | +Please check `requirements.txt` to install dependencies manually or execute: |
| 57 | +```bash |
| 58 | +python3 -m pip install -r requirements.txt |
| 59 | +``` |
| 60 | + |
| 61 | +### Preparing dataset |
| 62 | +[Terabyte Click Logs dataset of CriteoLabs (Criteo1t)](https://labs.criteo.com/2013/12/download-terabyte-click-logs/) contains feature values and click feedback for millions of display ads. Criteo1t contains 24 files, each one corresponding to one day of data. |
| 63 | + |
| 64 | +Each sample contains: |
| 65 | +- 1 label, 0 if the ad wasn't clicked and 1 if the ad was clicked |
| 66 | +- 13 dense features taking integer values, some values are `-1` |
| 67 | +- 26 categorical features, some features may have missing values |
| 68 | + |
| 69 | +In our data preprocess, the label is mapped to integer, literal `1` is added to dense features, there are two options for categorical features: |
| 70 | +1. The index count of each features is limited to `mod_idx`(40 million as default), and offset `mod_idx * i` is added to the limited value to make sure each column has different ids, `i` stands for column id. |
| 71 | +2. The original 32 bits hashed value is hashed onto 64 bits alone with column id `i` to make sure each column has different ids. |
| 72 | + |
| 73 | +Please find `tools/criteo1t_parquet.py` for more information. Except `input_dir` and `output_dir`, there are a few more arguments to run `tools/criteo1t_parquet.py`: |
| 74 | +- `spark_tmp_dir`: change the tmp directory used by pyspark, SSD of 2T or above is recommended |
| 75 | +- `spark_driver_memory_gb`: amount of gigabyte memory to use for the driver process, 360 as default |
| 76 | +- `mod_idx`, limited value of index count of each features, `0` or less stands for no limit |
| 77 | +- `export_dataset_info`, export `README.md` file in `output_dir` contains subsets count and table size array |
| 78 | + |
| 79 | +Please install `pyspark` before running. |
| 80 | + |
| 81 | +```bash |
| 82 | +python tools/criteo1t_parquet.py \ |
| 83 | + --input_dir=/path/to/criteo1t/day0-day23 \ |
| 84 | + --output_dir=/path/to/dlrm_parquet \ |
| 85 | + --spark_tmp_dir=/spark_tmp_dir \ |
| 86 | + --export_dataset_info |
| 87 | +``` |
| 88 | + |
| 89 | +## Start training by Oneflow |
| 90 | +Following command will launch 8 oneflow dlrm training and evaluation processes on a node with 8 GPU devices, by specify `data_dir` for data input and `persistent_path` for OneEmbedding persistent store path. |
| 91 | + |
| 92 | +`table_size_array` is close related to sparse features of data input. each sparse field such as `C1` or other `C*` field in criteo dataset corresponds to a embedding table and has its own capacity of unique feature ids, this capacity is also called `number of rows` or `size of embedding table`, the embedding table will be initialized by this value. `table_size_array` holds all sparse fields' `size of embedding table`. `table_size_array` is also used to estimate capacity for OneEmbedding. |
| 93 | + |
| 94 | +```python |
| 95 | +python3 -m oneflow.distributed.launch \ |
| 96 | + --nproc_per_node 8 \ |
| 97 | + --nnodes 1 \ |
| 98 | + --node_rank 0 \ |
| 99 | + --master_addr 127.0.0.1 \ |
| 100 | + dlrm_train_eval.py \ |
| 101 | + --data_dir /path/to/dlrm_parquet \ |
| 102 | + --persistent_path /path/to/persistent \ |
| 103 | + --table_size_array "39884407,39043,17289,7420,20263,3,7120,1543,63,38532952,2953546,403346,10,2208,11938,155,4,976,14,39979772,25641295,39664985,585935,12972,108,36" |
| 104 | +``` |
0 commit comments